Использование Selenium на практике
Вопросы
1) Document Object Model (объектная модель документа) 2) Блочные элементы DOM 3) Строчные элементы DOM 4) Поиск элементов на странице 5) Поиск по составным селекторам 6) Поиск элементов при помощи XPath 7) Запуск браузера с расширениями 8) Запуск браузера в скрытом режиме 9) Основные методы Selenium 10) Cookies
Document Object Model (объектная модель документа)
Каждый сайт в интернете можно просмотреть не только в виде оформленной страницы с картинками, но и в текстовом виде HTML. Именно из этого кода мы будем извлекать необходимую информацию.
DOM (Document Object Model) — набор правил, согласно которым формируется каждая веб страница с использованием языка разметки HTML. DOM хранит структуру сайта в виде дерева и информацию, заключённую в тегах.
Каждый элемент этого дерева называется узлом. Узлы могут иметь неограниченную вложенность. Однако не рекомендуется делать эту вложенность слишком глубокой: чем больше уровней, тем сложнее ориентироваться в коде и тем медленнее работает страница.
Вложенность тегов HTML можно сравнить с вложенностью обычных папок на персональном компьютере. Отличие заключается в том, что каждый узел DOM имеет своё название, атрибуты и специфическую функцию. Например, тег <title></title> указывает браузеру, какое название должно быть у вашей страницы на вкладке браузера, как его следует обработать и какие могут быть у него атрибуты.
Пример структуры HTML
<!DOCTYPE html> <!-- Объявление типа документа -->
<html> <!-- Корневой элемент -->
<head> <!-- Секция с метаданными -->
<meta charset="UTF-8"> <!-- Кодировка страницы -->
<title>Интернет-магазин</title> <!-- Заголовок страницы -->
<!-- Стили CSS -->
<style>
/* CSS для оформления карточки товара */
.product-card {
border: 1px solid #ccc;
padding: 15px;
width: 300px;
}
.product-title {
font-size: 1.2em;
}
.product-price {
color: #e44d26;
}
</style>
</head>
<body> <!-- Тело страницы -->
<h1>Каталог товаров</h1> <!-- Главный заголовок -->
<!-- Карточка товара -->
<div class="product-card" id="product-1"> <!-- Контейнер товара -->
<h2 class="product-title">Название товара</h2> <!-- Заголовок товара -->
<img src="product-image.jpg" alt="Изображение товара" width="100"> <!-- Изображение -->
<p class="product-description">Описание товара, которое подробно расскажет о его характеристиках.</p> <!-- Описание -->
<p class="product-price">Цена: 1000 руб.</p> <!-- Цена -->
<button type="button" onclick="addToCart('product-1')">Добавить в корзину</button> <!-- Кнопка -->
</div>
</body>
</html>
В данном примере мы видим типичную структуру html:
<title> - название страницы в браузере, отображается во вкладке.
<style> - стили для оформления карточки, чаще указывает на файл со стилями.
<div class="product-card"> - контейнер товара с классом по которому можно найти группу тегов.
<h2 class="product-title"> - название товара, тоже помогает найти группу тегов.
<img> - изображение товара с атрибутами src, alt и width
<p class="product-description"> - описание товара
<p class="product-price"> - цена товара
<button> - кнопка добавления в корзину
Каждый тег в этом примере — это узел в DOM-дереве. Узлы могут иметь любые атрибуты (например, src="product-image.jpg" для тега <img>) и вложенные узлы (например, <h2> вложен в <body>).
Визуальное представление DOM-дерева для нашего примера:
Document
└── html
├── head
│ ├── meta
│ ├── title
│ └── style
└── body
├── h1
└── div.product-card
├── h2.product-title
├── img
├── p.product-description
├── p.product-price
└── button
Практическое применение DOM
Дерево DOM служит инструментом для поиска нужного элемента на странице и взаимодействия с ним. При создании парсеров не требуется выполнять какие-то изменения в узлах DOM. Главное — понимать структуру DOM и знать, как получить доступ к определённому узлу и информации в нём.
Замечания
Каждый элемент в DOM имеет уникальный путь от корня документа, аналогично каталогам ПК.
Элементы могут быть найдены по их тегам, классам, ID, атрибутам или path.
DOM позволяет легко перемещаться между элементами (родительские, дочерние, соседние элементы)
При парсинге важно учитывать динамический характер DOM (элементы могут изменяться)
Блочные элементы DOM
Понимание разницы между блочными и строчными элементами критически важно для эффективной автоматизации веб страниц с помощью Selenium. Блочные элементы формируют основную структуру страницы и часто содержат важные данные, которые нам нужно извлечь.
Блочные элементы с точки зрения парсинга:
| Особенность | Описание | Пример использования |
|---|---|---|
| Структурная Организация | Блочные элементы часто служат контейнерами для других блочных или строчных элементов. Это делает их хорошими кандидатами для извлечения группы данных. | div.product-card для извлечения всех карточек товаров |
| CSS Селекторы | Из-за их структурной роли, блочные элементы часто имеют уникальные классы или идентификаторы, что упрощает их выборку. | article.main-content для поиска основного контента |
| Контекстуальная Информация | Поскольку блочные элементы часто содержат другие элементы, они могут предоставить контекст для извлекаемых данных. | section.product-info для получения всей информации о товаре |
| Стабильность | Блочные элементы обычно менее подвержены изменениям на динамически загружаемых веб-страницах, что делает их более надежными для автоматизации. | Использование main для поиска основного контента |
| Количество | В целом, блочных элементов обычно меньше, чем строчных, что может упростить процесс автоматизации | Поиск по article вместо множества span |
Практический пример автоматизации
Нам нужно извлечь все данные из блочного элемента <div> с классом description, в котором находится описание товара.
from selenium import webdriver
from selenium.webdriver.common.by import By
# Инициализация браузера
browser = webdriver.Chrome()
# Открываем страницу
browser.get("https://parsinger.ru/html/watch/1/1_5.html")
# Находим блочный элемент
product = browser.find_element(By.CLASS_NAME, "description")
# Извлекаем весь текст из элемента
data = product.text
# Выводим данные
print(data)
# Закрываем браузер
browser.quit()
# Вывод:
Умные часы GT RUNNER-B19S BLACK HUAWEI
Артикул: 80616445
Бренд: Huawei
Модель: GT RUNNER-B19S
Тип: умные часы
Технология экрана: AMOLED
Материал корпуса: пластик
Материал браслета: силикон
Размеры: 46.4 х 46.4 х 11 мм
Сайт производителя: www.huawei.ru
В наличии: 10
27770 руб
30170 руб
Купить
Особенности блочных элементов
Особенности отображения:
Блоки располагаются вертикально, один под другим.
Вставлять блочные элементы внутрь строчных запрещено.
Блоки занимают всё доступное пространство по ширине контейнера.
Высота блока вычисляется автоматически на основе его содержимого.
Примеры блочных элементов:
<div> - Универсальный блочный контейнер
<p> - Параграф текста
<h1>...<h6> - Заголовки разных уровней (от h1 — наиболее важный, до h6 — наименее важный)
<ul> - Маркированный список
<ol> - Нумерованный список
<li> - Элемент списка
Частые ошибки при автоматизации блочных элементов
Игнорирование вложенности элементов
Неправильный выбор локатора (слишком общий или слишком специфичный)
Неучет динамической загрузки контента
Попытка извлечь данные из неправильного уровня вложенности
Строчные элементы DOM
Строчные элементы - это фундаментальные компоненты HTML, которые используются для форматирования текста внутри блочных элементов. Понимание их особенностей важно для точного извлечения данных при автоматизации с помощью Selenium.
Строчные элементы применяются для форматирования отдельных фрагментов текста. Они обычно содержат одно или несколько слов и не создают перенос строки до и после себя.
Строчные элементы с точки зрения автоматизации:
| Особенность | Описание | Пример использования |
|---|---|---|
| Специфичность | Строчные элементы часто содержат конкретные фрагменты данных, такие как текст ссылок, выделенный текст и т.д. | span.price для извлечения цены товара |
| Динамичность | Элементы, такие как ссылки или кнопки, могут быть динамически загружены или изменены, что может создать проблемы при автоматизации. | Ожидание загрузки динамического контента |
| Вложенность | Строчные элементы часто вложены в блочные, и это может быть использовано для извлечения более точных данных. | div.product a.title для поиска ссылок в карточках товаров |
| Множественность | Они часто повторяются внутри блочных элементов, что может требовать более сложной логики автоматизации для извлечения всех необходимых данных. | Извлечение всех ссылок из списка |
| Ограниченный Контекст | Строчные элементы редко предоставляют контекстуальную информацию, поскольку они обычно фокусируются на конкретных данных. | Поиск по родительскому элементу для получения контекста |
Практический пример автоматизации
<div class="product">
<span class="price">1000 ₽</span>
<a href="/product/1" class="title">Наушники Hoco EQ2 Black</a>
<span class="stock">В наличии: 21</span>
</div>
from selenium import webdriver
from selenium.webdriver.common.by import By
#Инициализация браузера
browser = webdriver.Chrome()
# Открываем страницу
browser.get("https://parsinger.ru/3.2/simple_product_page.html")
# Находим карточку товара
product = browser.find_element(By.CLASS_NAME, "product")
# Извлекаем данные из строчных элементов
price = product.find_element(By.CLASS_NAME, "price").text
title = product.find_element(By.CLASS_NAME, "title").text
stock = product.find_element(By.CLASS_NAME, "stock").text
# Выводим данные
print(f"Цена: {price}") # Вывод - Цена: 1000 ₽
print(f"Название: {title}")# Вывод - Название: Наушники Hoco EQ2 Black
print(f"Наличие: {stock}")# Вывод - В наличии: 21
# Закрываем браузер
browser.quit()
Особенности строчных элементов
Особенности отображения:
Строчные элементы, расположенные подряд, отображаются на одной строке.
При необходимости, они автоматически переносятся на следующую строку.
Внутрь строчных элементов можно вставлять текст или другие строчные элементы.
Вставка блочных элементов запрещена.
Примеры строчных элементов:
<span> - Универсальный строчный контейнер
<a> - Гиперссылка
<img> - Изображение
<br> - Принудительный перенос строки
<strong> - Важный текст (обычно жирный
Ключевые HTML Атрибуты
При автоматизации веб страниц основная цель — извлечь нужную информацию из хаоса HTML-тегов. Атрибуты элементов играют роль своеобразных "якорей" или "указателей", которые помогают нам точно находить и идентифицировать необходимые данные. Знание основных атрибутов и понимание их роли в структуре документа критически важно для эффективной автоматизации. Давайте рассмотрим наиболее полезные атрибуты с точки зрения извлечения данных.
Атрибут id Уникальный идентификатор элемента на всей странице может быть только один id. Так как id должен быть уникальным, это самый надежный способ найти конкретный, единственный в своем роде элемент. Если у нужного вам блока данных есть id, поиск значительно упрощается.
<div id="user-profile">Информация о пользователе...</div>
# Найти элемент по его уникальному id
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
user_div = browser.find_element(By.ID, 'user-profile')
Атрибут class Задает один или несколько классов для элемента. Классы используются для группировки элементов (например, все карточки товаров могут иметь класс product-card) и для применения стилей CSS.
Классы — один из самых частых способов найти группу однотипных элементов. Если нужно извлечь все товары, все новости или все комментарии, поиск по общему классу будет вашим основным инструментом.
<div class="product-card">Карточка товара...</div>
<div class="product-card">Другая карточка...</div>
# Найти все элементы с классом 'product-card'
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
all_products = browser.find_elements(By.CLASS_NAME, 'product-card')
# Найти элемент с двумя классами 'product-card' и 'featured'
featured_product = browser.find_element(By.CSS_SELECTOR, '.product-card.featured')
Атрибут href
Задает URL-адрес для ссылок (тег <a>). Крайне важен и не заменим для извлечения URL-адресов. Это основной способ собрать необходимые ссылки со страницы, например, для перехода на следующие страницы (пагинация) или для скачивания файлов.
<a href="/catalog/item1">Ссылка на товар 1</a>
Пример поиска/извлечения (Selenium):
# Найти все ссылки и извлечь их URL
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
all_links = browser.find_elements(By.TAG_NAME, 'a')
for link in all_links:
url = link.get_attribute('href')
print(url)
Атрибут src
Указывает источник (URL) для медиа-элементов, таких как изображения (<img>), скрипты (<script>), фреймы (<iframe>). Используется для извлечения URL-адресов изображений, видео или других встраиваемых ресурсов. Если вам нужно скачать все картинки со страницы, вы будете искать теги и извлекать значение их атрибута src.
<img src="/images/product1.jpg" alt="Фото товара 1">
Пример поиска/извлечения (Selenium):
# Найти все изображения и извлечь их URL
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
all_images = browser.find_elements(By.TAG_NAME, 'img')
for img in all_images:
img_url = img.get_attribute('src')
print(img_url)
Атрибут alt
Задает альтернативный текст для изображений (тег <img>). Этот текст отображается, если изображение не может быть загружено, и используется программами чтения с экрана.
Иногда alt текст содержит полезное описание изображения, которое можно использовать как данные (например, название товара или краткое описание). Это может быть дополнительным источником информации.
<img src="/images/product1.jpg" alt="Смартфон 'Модель X' черный">
Пример извлечения (Selenium):
# Извлечь описание из атрибута alt
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
image = browser.find_element(By.TAG_NAME, 'img')
description = image.get_attribute('alt')
print(description) # Вывод: Смартфон 'Модель X' черный
Атрибут title Предоставляет дополнительную информацию об элементе в виде всплывающей подсказки при наведении курсора мыши. Реже используется для ключевых данных, но иногда в title может содержаться полезная информация, недоступная в основном тексте элемента, например, полное название или уточнение.
<span title="Международный стандартный книжный номер">ISBN</span>
# Извлечь текст подсказки
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
span_tag = browser.find_element(By.TAG_NAME, 'span')
full_description = span_tag.get_attribute('title')
print(full_description) # Вывод: Международный стандартный книжный номер
Атрибут style Используется для применения встроенных CSS-стилей непосредственно к элементу. Обычно напрямую не используется для автоматизации, но иногда стиль может указывать на состояние элемента (например, style="display: none;" означает, что элемент скрыт). Анализ стилей может помочь отфильтровать видимые элементы от скрытых, если это необходимо.
<div style="color: red; font-weight: bold;">Важное сообщение!</div>
<span style="display: none;">Скрытая информация</span>
Пример анализа (Selenium):
# Найти видимый элемент
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
div = browser.find_element(By.TAG_NAME, 'div')
style_attribute = div.get_attribute('style')
if 'display: none' not in style_attribute:
print("Элемент видим:", div.text)
Атрибуты data-*
Пользовательские атрибуты данных, предназначенные для хранения дополнительной информации об элементе, которая не связана со стилями или стандартным поведением.
Очень полезны! Веб-разработчики часто используют data-* атрибуты для хранения машиночитаемых данных, таких как ID товара, артикул, цена без форматирования, URL для AJAX-запроса и т.д. Это может быть золотой жилой для автоматизации, так как данные часто представлены в удобном для извлечения формате.
<button class="add-to-cart" data-product-id="12345" data-price="99.99">Добавить в корзину</button>
Пример извлечения (Selenium):
# Извлечь данные из data-атрибутов
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
button = browser.find_element(By.CLASS_NAME, 'add-to-cart')
product_id = button.get_attribute('data-product-id')
price = button.get_attribute('data-price')
print(f"ID товара: {product_id}, Цена: {price}") # Вывод: ID товара: 12345, Цена: 99.99
Понимание этих атрибутов и умение их использовать при поиске элементов обеспечивает создание эффективных и надежных скриптов автоматизации.
Поиск элементов на странице
Откроем страницу в браузере, и вызовим инструменты разработчика, нажав клавишу F12.
Далее откроем панель поиска по дереву HTML, используя комбинацию клавиш Ctrl+F.
Именно здесь мы будем проверять наши селекторы.
Поиск по #id
Символ "#" служит базовым селектором для поиска элементов по значению атрибута id. Этот метод особенно удобен, так как каждый id на веб-странице является уникальным. Следовательно, можно быть уверенным, что в HTML-документе найдется только один элемент с указанным id.
Для выполнения поиска по id применяется синтаксис вида #значение_атрибута. В качестве примера возьмем #brand.
Альтернативно, можно воспользоваться синтаксисом с квадратными скобками: [id='brand']. Этот метод дает такой же результат, как и #brand, но требует ввода большего количества символов. Выбор метода зависит от ваших личных предпочтений и сценария использования.
Ключевой момент для Selenium: Понимание работы с селектором # очень важно. Отобранный по id элемент чаще всего служит надежной точкой доступа к конкретному тегу и информации на странице. Поскольку id уникален, ошибочный сбор данных исключается, что существенно повышает надежность вашего скрипта.

Поиск по .class
Символ "." является базовым селектором, позволяющим выбирать элементы по имени класса. Синтаксис весьма прост и понятен: .имя_класса, например, .description. Как альтернатива, можно использовать синтаксис с квадратными скобками: [class="headers"].
⚠️ Важно отметить: При использовании селектора класса возможно получение нескольких элементов, поскольку один и тот же класс может быть присвоен разным элементам на странице. Это отличает поиск по классу от поиска по id, где каждый идентификатор уникален.
Применение в Selenium: Если ваша цель — получить все элементы с определенным классом (например, все карточки товаров), данный метод будет крайне полезен. Но если необходимо найти конкретный элемент из группы с одинаковым классом, возможно, придется дополнительно фильтровать результаты или использовать другие, более точные селекторы (например, комбинированные, о которых поговорим позже).
Поиск по имени тега
Самый простой способ отыскать определённый тег — это ввести его имя в строке поиска разработчика браузера. Например, headers или div. Этот метод особенно полезен, если вам нужно получить все элементы данного типа на странице — например, все абзацы, обозначенные тегом <p>.
Если вы ищете тег, состоящий из одного символа, такой как a или p, будьте внимательны! В результатах поиска появятся не только соответствующие теги, но и все вхождения этих символов в тексте на странице. <meta name="viewport"> или
Для точного поиска только тегов используйте угловые скобки в вашем запросе, например:
<a>или<p>в поле поиска инструментов разработчика. При написании селекторов для скрипта достаточно просто имени тега: browser.find_element(By.CSS_SELECTOR, "a")Метод поиска по имени тега является одним из наиболее базовых и распространённых. Он часто используется в качестве отправной точки для дальнейшего уточнения селекторов или комбинирования с другими методами поиска. Однако, следует помнить о тонкостях, таких как вхождение символов в текст при поиске в DevTools, чтобы избежать неточностей.
Поиск по значению атрибута [атрибут="значение"]
Мы уже упоминали использование квадратных скобок как альтернативу для поиска по id ([id='brand']) и class ([class="headers"]). Однако это лишь вершина айсберга: квадратные скобки позволяют выполнять поиск по любым атрибутам и их значениям!
Например, для поиска элемента с атрибутом name равным "4_1", вы можете применить синтаксис [name="4_1"]. И вы будете абсолютно правы в своём выборе. Аналогично можно искать по href, src, title, data-* и любым другим атрибутам.
Примеры:
Найти ссылку на главную: [href="/"]
Найти изображение по источнику: [src="images/logo.png"]
Найти элемент с определенным data-атрибутом: [data-product-id="123"]
Такой метод поиска вернет все элементы с указанным атрибутом и значением на веб-странице. Это может оказаться полезным, если вам нужно собрать все подобные элементы, но также может потребовать уточнений, если ваша задача требует большей специфичности.
Поиск по составным селекторам
В большинстве случаев мы можем напрямую обратиться к нужному элементу и извлечь его данные, используя простые селекторы, которые мы рассмотрели ранее. Однако иногда нас ждут неожиданные препятствия.
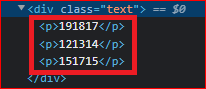
Представьте ситуацию: на странице есть два элемента с одинаковым классом (например, .price), но они размещены в разных родительских блоках (один в шапке, другой в карточке товара). Как нам извлечь цену именно из карточки товара?
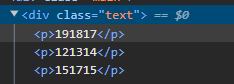
В этом примере оба тега <p> имеют одинаковый класс .text. Для того, чтобы получить тег, родительский элемент которого имеет класс "author", нам и потребуется составной селектор.
Селектор потомка (пробел)
Символ пробела " " в составном CSS-селекторе служит для выбора элементов, которые являются потомками заданного родителя, независимо от уровня их вложенности. То есть, селектор .author .text будет искать все элементы с классом text, которые находятся внутри элемента с классом author, неважно, насколько глубоко.
.author .text - это означает: "найди мне элемент с классом text, у которого где-то выше по дереву есть родитель (или прародитель, прапрародитель и т.д.) с классом author". Между ними может быть сколько угодно других тегов и уровней вложенности.
Проверка: Это утверждение легко проверить. У нас есть структура данных по ссылке. Селектор .author .text найдёт необходимый тег, несмотря на то, что он находится на глубине вложенности в четыре уровня от родительского элемента .author.

Используем селектор .container .price_box p на этом сайте для поиска тега `<p>` внутри элемента с классом price_box, который сам находится внутри элемента с классом container.

Селектор прямого потомка (>)
Символ ">" (знак "больше") — используется для выбора непосредственных дочерних элементов относительно указанного родительского элемента. В отличие от пробела, он не ищет глубже первого уровня вложенности.
.img_box > .name_item — данный синтаксис позволяет нам точно определить и выбрать элемент с классом .name_item, который является прямым дочерним элементом (англ. "child") элемента с классом .img_box. В этом случае, .img_box выступает в роли родительского элемента (англ. "parent"). Если .name_item будет вложен еще глубже (например, внутри другого div внутри .img_box), этот селектор его не найдет.

Поиск по порядковому номеру дочернего элемента (:nth-child())
Псевдокласс :nth-child(n) — этот синтаксис чрезвычайно полезен, когда вам нужно выбрать конкретный дочерний элемент по его порядковому номеру среди своих "братьев" (элементов на том же уровне вложенности с тем же родителем).
#description > li:nth-child(3) — в данном примере мы ищем третий по счету элемент `<li>`, который является прямым потомком элемента с id="description".
Замечание: В большинстве языков программирования индексация списков и массивов начинается с 0. Однако, в CSS селекторах, таких как :nth-child(), счёт начинается с 1! Это одна из тех мелочей, которую просто необходимо запомнить, чтобы избежать ошибок и неточностей при парсинге.

Использование двух и более классов одновременно (без пробела)
Иногда HTML-элемент может иметь сразу несколько классов, например: <div class="product featured promo">. Если вам нужно найти элемент, который имеет одновременно два (или более) конкретных класса, вы можете просто написать их имена через точку, без пробела между ними.
Селектор .class1.class2 найдет элемент, у которого в атрибуте class есть и class1, и class2.
Это особенно полезно, когда вы сталкиваетесь с более сложными структурами HTML, где одни и те же классы могут использоваться в разных контекстах или комбинациях. С помощью такой "стыковки" классов вы сможете точнее находить нужные вам теги.
Ключевой момент: Отсутствие пробела между именами классов (.class1.class2) говорит парсеру: "Ищи элемент, который имеет ОБА этих класса одновременно". Если вы поставите пробел (.class1 .class2), это будет означать поиск потомка (элемент с class2 внутри элемента с class1), как мы обсуждали ранее.
.main.author - такой составной селектор используется для поиска элемента, у которого есть и класс main, и класс author.

Поиск элементов при помощи XPath
XPath — это язык, который используется для навигации по элементам в XML или HTML-документах. В контексте Selenium XPath помогает найти нужные элементы на веб-странице. Постараюсь объяснить это максимально просто.
Основные принципы XPath:
Поиск по тэгу (элементу):
Если на странице есть элементы типа <p>, то с помощью XPath можно найти их, указав просто название тега:
`//p`
Это найдет все теги <p> на странице.
Поиск по атрибутам: Если у элемента есть атрибут, например class, то можно найти его по этому атрибуту. Например, у нас есть такой элемент:
`<p class="text">Это параграф с классом text</p>`
Для поиска по атрибуту class пишем:
//*[@class="text"]
Это найдет элемент с классом text.
Поиск по тексту внутри элемента:
Если нужно найти элемент, который содержит определенный текст, используем функцию text(). Например:
<p>Привет, мир!</p>
<p>Как дела?</p>
Чтобы найти параграф с текстом "Как дела?", напишем:
//p[text()="Как дела?"]
Поиск по частичному совпадению текста:
Если текст в элементе может быть разным, но начинается или заканчивается с определенной фразы, можно использовать функцию contains(). Например:
//p[contains(text(), "Как")]
Это найдет все теги <p>, которые содержат слово "Как".
Поиск с использованием нескольких условий:
XPath позволяет комбинировать условия. Например, если нужно найти <p> с классом text и с текстом "Как дела?", то пишем:
//p[@class="text" and text()="Как дела?"]
Поиск дочерних элементов:
Если элемент находится внутри другого, используем / для перехода по уровням. Например:
<div>
<p>Это параграф внутри div</p>
</div>
Чтобы найти параграф внутри div, пишем:
//div/p
Поиск по индексу:
Иногда нужно выбрать элемент по его порядковому номеру. Например, если нужно выбрать второй параграф:
//p[2]
Это выберет второй параграф на странице.
Пример использования XPath в Selenium:
Предположим, у нас есть такой HTML-код:
<html>
<body>
<div class="content">
<p class="text">Первый параграф</p>
<p class="text">Второй параграф</p>
</div>
</body>
</html>
Чтобы выбрать второй параграф с помощью XPath, напишем код в Selenium:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://example.com") # Замените на URL страницы
# Ищем второй параграф
element = driver.find_element_by_xpath('//p[2]')
print(element.text)
driver.quit()
Этот код найдет второй параграф на странице и выведет его текст.
XPath — это инструмент для поиска элементов на веб-странице. На практике ты будешь комбинировать эти методы для точного выбора нужных элементов.
Запуск браузера с расширениями
Чтобы запустить браузер с уже установленным расширением, сначала нам нужно подготовить это расширение. В Chrome есть магазин расширений.
Расширение "coordinates" теперь недоступно в магазине расширений расширение, которое поможет определить координаты курсора называется "Mouse Coordinates". Установите его можно привычным образом, как вы обычно устанавливаете расширения в Chrome.
📦Чтобы подготовить расширение для работы, нам необходимо его упаковать. Для этого запустим Chrome и перейдем в раздел расширений chrome://extensions ("Меню" → "Настройки" → "Расширения") → далее отметим чекбокс (флажок) "Режим разработчика" → "Упаковать расширение" (скриншот) укажем путь где лежит расширение, а в частности файл manifest.json → "ОК".

Нажимаем на "Упаковать расширение" и в появившемся окне, укажите путь к нужному вам расширению.

🪟 Для Windows:
Путь до папки с расширениями на Windows обычно выглядит так:
C:\Users\[Ваш_пользователь]\AppData\Local\Google\Chrome\User Data\Default\Extensions
🍎Для macOS:
Путь для macOS чаще всего такой: ~/Library/Application Support/Google/Chrome/Default/Extensions
🐧Для Linux:
Путь в Linux: ~/.config/google-chrome/Default/Extensions
Или в адресной строке браузера пишем chrome://version/ и найдите там путь к папке Default в которой хранятся все расширения. Это самый простой способ найти нужную папку, если вы не уверены в точном расположении.

Обратите внимание что создаётся 2 файла:
0.2_0.crx - упакованное расширение, это основной файл, который мы будем использовать.
0.2_0.pem - файл ключей, который необходимо будет удалить если, потребуется повторная упаковка расширения (имя будет соответствовать названия расширения).

Путь к расширению может выглядеть подобным образом, где Default это имя вашего профиля =>
C:\Users\user\AppData\Local\Google\Chrome\User Data\Default\Extensions\ghbmnnjooekpmoecnnnilnnbdlolhkhi\
Все расширения имеют странные названия, примерно такие как на изображении ниже, чтобы найти то, которое только что упаковали, найдите его по идентификатору

После упаковки расширения в каталоге появится файл "0.2_0.crx", это и есть наше упакованное расширение, теперь оно готово к использованию. Осталось добавить его в Selenium.

Добавляем "0.2_0.crx" в Selenium
Для удобства переименуем файл 0.2_0.crx в coordinates.crx
В методе .add_extension('coordinates.crx') мы указываем путь к упакованному расширению. Если расширение находится в каталоге с проектом, достаточно указать только его имя.
Также необходимо передать опции в webdriver. Э то делается так: webdriver.Chrome(options=). Опции позволяют настроить браузер под наши нужды.
import time
from selenium import webdriver
options_chrome = webdriver.ChromeOptions()
# UPDATE в 137 CHROME добавляйте еще строку:
options_chrome.add_argument("--disable-features=DisableLoadExtensionCommandLineSwitch")
options_chrome.add_extension('coordinates.crx')
with webdriver.Chrome(options=options_chrome) as browser:
url = 'https://stepik.org/course/104774'
browser.get(url)
time.sleep(15)
Если все сделано правильно, при запуске браузера с Selenium, в нём будет установлено наше расширение.
Перед запуском кода, установите достаточную задержку, чтобы запустить его у себя и убедиться в этом самостоятельно.

Когда полезно запускать Selenium c расширениями?
-
Блокировка рекламы: Если тестирование веб-сайта затруднено из-за рекламы, можно использовать расширения типа AdBlock для их блокировки.Это делает тесты более стабильными и быстрыми.
-
Повышение безопасности: Расширения вроде HTTPS Everywhere могут обеспечить шифрование трафика, что актуально для тестирования веб-сайтов с фокусом на безопасности.Это особенно важно при работе с конфиденциальными данными.
-
Эмуляция мобильных устройств: Некоторые расширения позволяют эмулировать мобильный браузер, что может быть полезно для тестирования адаптивных веб-сайтов.
-
Манипуляции с куками: Расширения типа EditThisCookie дают возможность быстро изменять или удалять куки прямо в браузере.Это полезно для тестирования различных состояний авторизации.
-
Отладка и анализ: Расширения вроде Firebug или Developer Tools могут быть полезными для быстрой отладки и анализа веб-страниц. Они помогают найти проблемы в структуре страницы.
-
Скриншоты и запись экрана: Для документации ошибок или для создания инструкций можно использовать расширения для создания скриншотов или видеозаписи экрана.Это отлично подходит для создания отчетов о тестировании.
-
Специфичные нужды: Некоторые тестовые сценарии могут требовать очень специфических действий, которые можно автоматизировать с помощью специализированных расширений.Это расширяет возможности автоматизации.
-
Смена User-Agent: Некоторые сайты разрешают доступ только определённым браузерам или устройствам. Здесь на помощь придут расширения для смены User-Agent.Это позволяет обойти ограничения доступа.
Популярные расширения
-
AdBlock / uBlock Origin: для блокировки рекламы. Эти расширения значительно ускоряют загрузку страниц.
-
EditThisCookie: для работы с куками. Позволяет легко управлять сессиями.
-
User-Agent Switcher: для смены User-Agent. Полезно для тестирования мобильных версий сайтов.
-
Firebug / Chrome Developer Tools: для отладки и анализа. Незаменимы при поиске проблем в коде.
-
Screenshot: для скриншотов и записи экрана. Отлично подходит для документирования ошибок.
-
LastPass / 1Password: для автоматического заполнения форм, если это нужно в тестах. Упрощает процесс авторизации.
-
Proxy SwitchyOmega: для работы с прокси-серверами. Полезно для тестирования геолокационных функций.
-
Wappalyzer: для определения технологий, используемых на веб-сайте. Помогает понять, какие технологии используются на сайте.
-
Tampermonkey: Для запуска пользовательских скриптов, что может быть полезно для автоматизации сложных действий на веб-странице. Это мощный инструмент для расширения возможностей браузера.
Запуск браузера в скрытом режиме
Данный метод особенно полезен, когда есть задачи автоматизации, которые не требуют взаимодействия с пользовательским интерфейсом вручную, такие как веб-скрапинг или автоматизированное тестирование и др.
Запуск браузера в фоновом режиме очень прост: достаточно запомнить всего один параметр и синтаксис. Для этого нам потребуется передать параметр --headless или --headless=new в метод .add_argument(). В качестве примера откроем страницу курса и получим первую найденную ссылку.
from selenium import webdriver
from selenium.webdriver.common.by import By
# Создание объекта ChromeOptions для дополнительных настроек браузера
options_chrome = webdriver.ChromeOptions()
# Добавление аргумента '--headless' для запуска браузера в фоновом режиме
options_chrome.add_argument('--headless')
# Инициализация драйвера Chrome с указанными опциями
# Использование менеджера контекста 'with' для автоматического закрытия браузера после выполнения кода
with webdriver.Chrome(options=options_chrome) as browser:
url = 'https://stepik.org/course/104774'
browser.get(url)
# Ищем элемент по тегу 'a' (ссылку)
a = browser.find_element(By.TAG_NAME, 'a')
# Выводим атрибут 'href' найденного элемента (URL ссылки)
print(a.get_attribute('href'))
Настройка опций браузера: создается объект options_chrome, в который добавляется аргумент --headless для запуска браузера в фоновом режиме.
# Создание объекта ChromeOptions для дополнительных настроек браузера
options_chrome = webdriver.ChromeOptions()
# Добавление аргумента '--headless' для запуска браузера в фоновом режиме
options_chrome.add_argument('--headless')
Инициализация драйвера: после этого инициализируется драйвер Chrome с указанными опциями. Здесь используется менеджер контекста with, чтобы автоматически закрыть браузер после выполнения операций.
with webdriver.Chrome(options=options_chrome) as browser:
Открытие веб-страницы: Следующим шагом является открытие заданной веб-страницы по URL-адресу https://stepik.org/course/104774
url = 'https://stepik.org/course/104774'
browser.get(url)
Поиск элемента: Затем выполняется поиск первого элемента с тегом a на открытой странице.
# Ищем элемент по тегу 'a' (ссылку)
a = browser.find_element(By.TAG_NAME, 'a')
Преимущества запуска браузера в фоновом режиме
-
Отсутствует отрисовка содержимого: Поскольку браузер не отображает веб-страницы, потребление ресурсов (CPU и RAM) снижается.
-
Быстродействие: Нет необходимости в отрисовке элементов на странице, что ускоряет работу. Это особенно заметно на слабых машинах.
-
Экономия экранного пространства: Запущенный в фоновом режиме браузер не занимает место на экране и не мешает вашей текущей работе.
-
Повышенная стабильность: В фоновом режиме меньше вероятность сбоев из-за отсутствия взаимодействия с пользовательским интерфейсом.
-
Удобство автоматизации: Процесс становится более управляемым для автоматических скриптов и тестов, т.к. не требует открывания и закрывания окон.
-
Скрытность: В фоновом режиме более трудно для окружающих заметить, что именно вы делаете, что может быть полезно для сбора данных или тестирования.
-
Экономия времени: Вам не нужно ждать, пока страницы загрузятся и элементы отобразятся, что делает процесс более эффективным по времени.
-
Легкость интеграции: В фоновом режиме удобнее интегрировать веб-парсинг или автоматизацию браузера в большие системы или конвейеры обработки данных.
-
Уменьшение вероятности капчи: Некоторые сайты менее строго реагируют на запросы из браузера, запущенного в фоновом режиме, по сравнению с браузером, активно используемым пользователем.
Перенос профиля с основного браузера Chrome в браузер под управлением Selenium
Перенос профиля пользователя из основного браузера Chrome в браузер, управляемый через Selenium, позволяет сохранить все настройки, закладки и историю просмотров и т.д. Это может быть особенно полезно для автоматизации тестирования в условиях, максимально приближенных к реальному пользовательскому опыту, или для автоматизации задач без необходимости настройки профиля с нуля.
Определение пути к профилю Chrome:
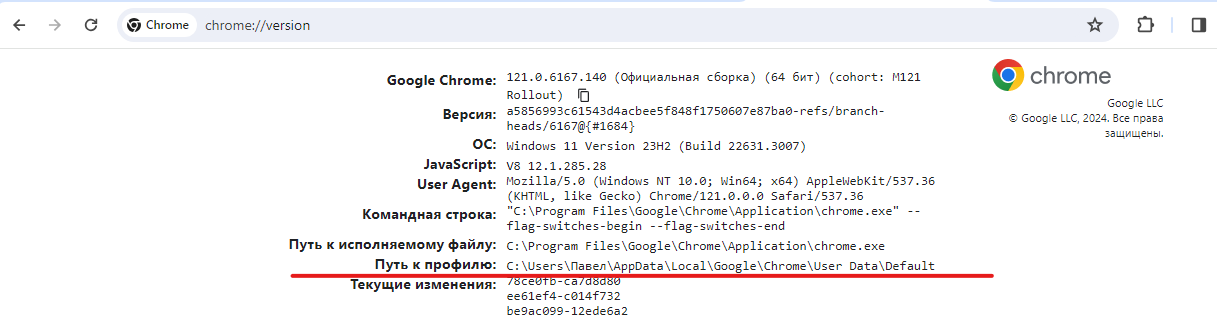
Откройте браузер Chrome и введите в адресной строке chrome://version/.
Найдите строку "Путь к профилю:" — это и будет путь к вашему профилю пользователя. Обычно он выглядит как C:\Users\[Имя пользователя]\AppData\Local\Google\Chrome\User Data.
Использование пути к профилю в Selenium:
Чтобы использовать этот профиль в Selenium, необходимо указать путь к директории профиля пользователя в качестве аргумента при инициализации драйвера браузера через ChromeOptions.
'user-data-dir=C:\\Users\\user\\AppData\\Local\\Google\\Chrome\\User Data' добавьте путь к профилю в метод .add_argument()
import time
from selenium import webdriver
# Задаем опции для Chrome
options_chrome = webdriver.ChromeOptions()
# Указываем путь к профилю пользователя
options_chrome.add_argument('user-data-dir=C:\\Users\\user\\AppData\\Local\\Google\\Chrome\\User Data')
# Инициализируем драйвер с указанными опциями
with webdriver.Chrome(options=options_chrome) as browser:
url = 'https://yandex.ru/'
browser.get(url) # Открываем страницу
time.sleep(10) # Даем время на загрузку страницы
Если все сделано правильно, то у вас запустится окно браузера с вашими параметрами, историей, закладками.
Если при запуске этого кода возникает ошибка, сообщающая, что директория данных пользователя уже используется (например, "invalid argument: user data directory is already in use, please specify a unique value for"), это означает, что ваш основной браузер Chrome в данный момент использует этот профиль. Вам нужно закрыть основной браузер и повторить попытку.
Если нужно одновременно работать с основным окном браузера и сессией Selenium, скопируйте папку User Data в другое место и укажите путь к этой копии в user-data-dir, как это делалось выше.
Основные методы Selenium
В своем распоряжении Selenium имеет большое количество методов, которые мы можем использовать. Здесь будут размещены почти все из них. Но, как показывает практика, пользоваться вы будете малой их частью. Про одни методы вы должны просто знать, что они существуют, про другие методы скорее всего даже вспоминать не придется, а какие-то методы очень полезны и мы порешаем задачки с их помощью, чтобы лучше закрепить их в памяти.
Для эффективного использования Selenium рекомендуется сначала освоить базовые методы, а затем постепенно изучать более сложные. Это позволит быстрее начать автоматизировать простые задачи.
Навигация по истории браузера
Эти методы особенно полезны при тестировании веб-приложений, где нужно проверить корректность работы навигации между страницами.
browser.back() - С помощью этого метода вы можете вернуться на предыдущую страницу, как если бы нажали стрелочку "назад" в браузере.
browser.forward() - Аналогично предыдущему, но перемещает вперёд по истории браузера.
browser.refresh() - Этот метод обновляет текущую страницу, как если бы вы нажали кнопку обновления в браузере.
Работа со скриншотами Эти методы особенно полезны при тестировании веб-приложений, где нужно проверить корректность работы навигации между страницами.
browser.get_screenshot_as_file("../file_name.jpg") - Сохраняет скриншот страницы в файл по указанному пути. Возвращает True если всё прошло успешно, и False при ошибках ввода-вывода.
browser.save_screenshot("file_name.jpg") - Сохраняет скриншот в папке с проектом.
browser.get_screenshot_as_png() - Возвращает скриншот в виде двоичных данных (binary data), которые можно передать или сохранить в файл в конструкторе with/as;
browser.get_screenshot_as_base64() - Возвращает скриншот в виде строки в кодировке Base64. Удобно для встроенных изображений в HTML.
Открытие и закрытие страниц и браузера
browser.get("http://example_url.ru") - Открывает указанный URL в браузере.
browser.quit() - Закрывает все вкладки и окна, завершает процесс драйвера, освобождает ресурсы.
browser.close() - Закрывает только текущую вкладку.
Исполнение JavaScript
browser.execute_script("script_code") - Выполняет JavaScript код на текущей странице.
browser.execute_async_script("script_code" , *args ) - Асинхронно выполняет JavaScript код. Удобно для работы с AJAX и промисами.
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);") - прокрутка страницы вниз.
Время ожидания
browser.set_page_load_timeout() - Устанавливает таймаут на загрузку страницы. Выбрасывает исключение, если время вышло.
Установите разумный таймаут для предотвращения бесконечного ожидания загрузки страницы.
Поиск элементов
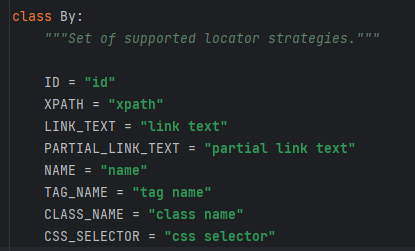
browser.find_element(By.ID, 'example_id') - Возвращает первый найденный элемент по заданному локатору.
browser.find_elements(By.ID, 'example_id') - Возвращает список всех элементов, соответствующих локатору.
Метод find_element выбросит исключение, если элемент не найден, в то время как find_elements вернет пустой список.
Работа с окном браузера
browser.get_window_position() - Возвращает словарь с текущей позицией окна браузера ({'x': 10, 'y': 50}).
browser.maximize_window() - Разворачивает окно на весь экран.
browser.minimize_window() - Сворачивает окно.
browser.fullscreen_window() - Переводит окно в полноэкранный режим, как при нажатии F11.
browser.get_window_size() - Возвращает размер окна в виде словаря ({'width': 945, 'height': 1020}).
browser.set_window_size(800,600) - Устанавливает новый размер окна.
Управление размером окна полезно для тестирования адаптивного дизайна или для работы с элементами, которые видны только при определенном разрешении.
Работа с cookies
browser.get_cookies() - Возвращает список всех cookies.
browser.get_cookie(name_cookie) - Возвращает конкретную cookie по имени.
browser.add_cookie(cookie_dict) - Добавляет новую cookie к вашему текущему сеансу;
browser.delete_cookie(name_cookie) - Удаляет cookie по имени.
browser.delete_all_cookies() - удаляет все файлы cookie в рамках текущего сеанса;
Работа с cookies часто необходима для эмуляции авторизованного пользователя или для тестирования функциональности, зависящей от состояния сессии.
Работа с элементами
element.click() - Симулирует клик по элементу.
element.send_keys("text") - Вводит текст в текстовое поле. Очень полезно для автоматизации ввода данных.
element.clear() - Очищает текстовое поле.
element.is_displayed() - Проверяет, отображается ли элемент на странице.
element.is_enabled() - Проверяет, доступен ли элемент для взаимодействия (например, не заблокирован).
element.is_selected() - Проверяет, выбран ли элемент (актуально для радиокнопок и чекбоксов).
element.get_attribute("attribute") - Возвращает значение указанного атрибута элемента.
element.text - Возвращает текст элемента.
element.submit() - Отправляет форму, в которой находится элемент.
Перед взаимодействием с элементом всегда проверяйте его видимость и доступность с помощью методов is_displayed() и is_enabled().
Cookies
Куки (cookie, буквально — «печенье») — это небольшой фрагмент данных, отправленный веб-сервером и хранимый на компьютере пользователя. Когда вы открываете сайт, сервер отправляет вашему браузеру данные, которые хранятся в его памяти.
Название "cookie" происходит от термина "magic cookie", который использовался в программировании Unix и обозначал пакет данных, передаваемый между программами.
Куки чаще всего используются для:
Аутентификации пользователя;
Хранения личных настроек на сайте, например, темной темы или сохранения товаров в корзине, если вы не залогинились на сайте;
Отслеживания состояния сеанса доступа пользователя;
Сбора статистики о пользователях;
Хранения информации о местоположении пользователя и IP-адресе;
Кликов и переходов;
Сбора информации об операционной системе и браузере;
И многого другого.
Cookies не являются персональными данными, так как в законе сказано, что персональные данные — это информация, позволяющая идентифицировать человека. Даже фамилия, имя и отчество могут не являться персональными данными, если требуются дополнительные сведения для определения личности человека. Не говоря уже о cookies.
Существует два вида cookie:
⏱Сессионные (временные) — хранят в себе информацию, которая актуальна на ближайшее время. К таким данным можно отнести записи форм, полей, время пребывания на сайте. Чаще всего они существуют, пока вы находитесь на сайте, и удаляются, как только вы его покидаете.
Постоянные - это куки, которые могут храниться в вашем браузере очень долго. Например, логин от вашей учетной записи на сайте или другие данные, связанные с вашей учетной записью, такие как данные о вашем местоположении в учетной записи Google.
Чтобы увидеть, какие cookie сохраняет сайт в вашем браузере, вам нужно открыть инструмент разработчика клавишей F12.

После нажатия F12 перейдите на вкладку "Application" (Chrome) или "Storage" (Firefox), затем найдите раздел "Cookies" в левой панели и выберите нужный домен.
.get_cookies()
В коде ниже использован метод .get_cookies(), который получает список всех cookie на странице.
from pprint import pprint
from selenium import webdriver
with webdriver.Chrome() as browser:
browser.get('https://ya.ru/')
cookies = browser.get_cookies()
pprint(cookies)
>>>
[{'domain': '.ya.ru',
'expiry': 1685518907,
'httpOnly': False,
'name': '_ym_d',
'path': '/',
'sameSite': 'None',
'secure': True,
'value': '1653982908'},
...
{'domain': '.ya.ru',
'expiry': 1656574906,
'httpOnly': False,
'name': 'yandex_gid',
'path': '/',
'sameSite': 'None',
'secure': True,
'value': '239'}]
.get_cookie(name_cookie)
В отличие от первого метода, этот метод находит и возвращает cookie по его имени.
Есть два способа определить имя
Способ №1 - этот способ не очень надежен, т.к. с "живого" браузера данные в cookies могут отличаться в зависимости от открытой сессии. Но если ваш код не зависит от параметров сессии, то можно получить имена cookie именно в браузере;

Способ №2 - мы можем в цикле for/in итерироваться по списку cookie, который мы получили с помощью метода .get_cookies() Этим способом мы можем получить не только имя cookie, но и его значение.
from selenium import webdriver
with webdriver.Chrome() as browser:
browser.get('https://ya.ru/')
cookies = browser.get_cookies()
for cookie in cookies:
print(cookie['name']) # или cookie['value'] чтобы получить их значение
>>>
_ym_d, _ym_isad, _ym_uid, my, gdpr, _yasc, i, is_gdpr, yuidss
yabs-frequency, is_gdpr_b, yandexuid, yp, mda, ymex, yandex_gid
Когда мы знаем имена всех cookie на странице, мы можем получить нужные нам данные по ключу. Мы помним, что .get_cookies() возвращает список словарей. Если вы посмотрите на первый пример с кодом, вы увидите, что в cookie хранится время экспирации 'expiry': 1685518907 т.е., время истечения срока жизни cookie. Пример кода ниже поможет нам извлечь конкретное значение из cookie.
from selenium import webdriver
with webdriver.Chrome() as browser:
browser.get('https://ya.ru/')
print(browser.get_cookie('_ym_uid')['expiry'])
>>>1685520499
Используйте второй способ для более надежного получения имен cookies, особенно если вы работаете с динамическими сайтами, где набор cookies может меняться.
.delete_cookie(name_cookie)
Удаляет только одну cookie по её имени.Cookies привязаны к домену. Если вы хотите удалить cookies для определённого сайта, сначала перейдите на этот сайт с помощью browser.get()
from selenium import webdriver
import time
with webdriver.Chrome() as browser:
url = "https://parsinger.ru/methods/3/index.html"
browser.get(url)
# Итерируемся по всем именам куков, в которых последнее число — чётное, и удаляем их.
for i in range(0,17,2):
browser.delete_cookie(f"secret_cookie_{i}")
time.sleep(30)
Перед удалением cookie убедитесь, что вы находитесь на правильном домене, иначе операция может не сработать.
.delete_all_cookies()
Метод delete_all_cookies() в Selenium используется для удаления всех кук текущей сессии браузера. Это может быть полезно, например, при необходимости очистить состояние между тестами или перед началом нового сценария.
Метод удаляет все куки , связанные с текущим доменом.
После вызова этого метода список кук (browser.get_cookies()) станет пустым.
Этот метод не зависит от типа куки (например, httpOnly или secure), он удаляет все без исключения.
from pprint import pprint
from selenium import webdriver
with webdriver.Chrome() as browser:
url = "https://parsinger.ru/methods/3/index.html"
browser.get(url)
# Получаем список существующих кук до удаления
print("Cookies before deletion:")
pprint(browser.get_cookies())
# Удаляем все куки
browser.delete_all_cookies()
# Проверяем, что куки удалены
print("\nCookies after deletion:")
pprint(browser.get_cookies())
browser.add_cookie(cookie_dict)
Все мы когда-то чистили браузер от печенек (cookies). Наверное, каждый начинающий программист знает, что если очистить cookies, то настройки сайта слетят: слетит учётная запись, тёмная тема перестанет загружаться по умолчанию, и сайт вдруг перестанет приветствовать вас по имени. Всем понятно, зачем чистить куки, но зачем их добавлять в браузер? Добавляем мы их по обратной причине. Когда работаем с Selenium, мы не всегда можем использовать один профиль браузера в нескольких скриптах. В таких случаях мы можем либо создать ещё несколько профилей, либо использовать одни cookies для всех скриптов.
Добавление cookies позволяет вам эмулировать авторизованного пользователя или сохранять настройки между сессиями без необходимости повторной авторизации.
.add_cookie(cookie_dict) — это метод, который добавляет cookie в ваш браузер. Он принимает словарь, но с определёнными ограничениями: мы не можем передать в cookie что угодно. В браузере есть заранее подготовленные поля, в которые мы можем передавать данные.
# Добавляет файл cookie в текущий контекст браузера.
browser.add_cookie({"name": "key", "value": "value"})
Доступные поля для cookie можно посмотреть в любом браузере. Эти поля доступны для передачи их в словаре. О том, как формировать словарь, мы поговорим ниже.
Параметры cookie
"name" — устанавливает имя cookie-файла;
"value" — устанавливает значение cookie; это значение может либо идентифицировать пользователя, либо содержать любую другую служебную информацию;
"expires" и "max-age" — определяют срок жизни cookie; после истечения этого срока, cookie будет удалён из памяти браузера. Если не указывать эти значения, содержимое cookie будет удалено после закрытия браузера;
"path" — указывает путь к директории на сервере, для которой будут доступны cookie. Чтобы cookie были доступны по всему домену, необходимо указать "/";
"domain" — хранит в себе информацию о домене или поддомене, которые имеют доступ к этой cookie. Если необходимо, чтобы cookie были доступны по всему домену и всем поддоменам, указывается базовый домен, например, www.example.ru;
"secure" — указывает серверу, что cookie должны передаваться только по защищённому HTTPS-соединению;
"httponly"— этот параметр запрещает доступ к cookie через JavaScript (API браузера document.cookie). Предотвращает кражу cookie посредством XSS-атак. Если флаг установлен в True, вы сможете получить доступ к этой cookie только через браузер, в том числе и через Selenium;
"samesite"— ограничивает передачу cookie между сайтами и предотвращает кражу cookie посредством XSS-атак. Имеет три состояния.
SameSite=None — на передачу cookie нет никаких ограничений;
SameSite=Lax — разрешает передачу только безопасным HTTP-методам;
SameSite=Strict или SameSite — самое строгое состояние, которое запрещает отправку cookie на другие сайты.
Практический пример
Запустите код ниже у себя в терминале, поиграйтесь с параметрами, посмотрите на результат, найдите изменения в браузере.
import time
from pprint import pprint
from selenium import webdriver
cookie_dict = {
'name': 'any_name_cookie', # Любое имя для cookie
'value': 'any_value_cookie', # Любое значение для cookie
'expiry': 2_000_000_000, # Время жизни cookie в секундах
'path': '/', # Директория на сервере дял которой будут доступны cookie
'domain': 'parsinger.ru', # Информация о домене и поддомене для которых доступны cookie
'secure': True, # or False # Сигнал браузера о том что передать cookie только по защищённому HTTPS
'httpOnly': True, # or False # Ограничивает достук к cookie по средствам API
'sameSite': 'Strict', # or lax or none # Ограничение на передачу cookie между сайтами
}
with webdriver.Chrome() as browser:
browser.get('https://parsinger.ru/methods/4/index.html')
browser.add_cookie(cookie_dict)
pprint(browser.get_cookies())
time.sleep(100)
В этом примере мы создаем cookie с именем 'any_name_cookie' и значением 'any_value_cookie'. Cookie будет доступна только на домене 'parsinger.ru' и только по защищенному HTTPS-соединению. Срок жизни cookie установлен на 2 миллиарда секунд (около 63 лет).
Все ключи словаря cookie_dict={} соответствуют полям cookie в браузере. Поэтому изменять ключи в этом словаре не рекомендуется: если вы это сделаете, ничего не произойдёт. Словарь просто не запишется в cookie браузера. Изменять можно только значения этого словаря, и то, следуя определённым правилам. Вы имеете полную свободу изменения только для значений ключей "name" и "value"; остальные значения в ключах подчиняются строгим правилам.
Это могут быть правила касающиеся времени жизни cookie (Expires, Max-Age), домена (Domain), пути (Path), флагов безопасности (Secure, HttpOnly) и так далее.
